# Lab05 Copy-on-Write Fork
hh实验只有一题但是是 hard
不过如果看完了视频的思路我觉得对这个和后续的实验都有帮助(教了一种做实验的思路,就是 bug 有时候是你故意想要的)
# 实验准备
git fetch
git checkout cow
make clean
得到相应的实验环境
# Implement copy-on write
首先我们要知道 COW 技术的原理:
- 当
fork一个进程的时候,COW并不会真的划分一个物理空间然后创建一个新页表进行映射。COW只是创建一个新页表,然后把这个页表映射到父进程的物理空间上,并设置PTE为只读(父子行程都是只读) - 当我们需要对子进程进行操作的时候(这当然是写操作),这个时候我们才会为子进程分配物理空间,然后设置
PTE为可写
流程就是这么简单……
显然,我们应该从 fork 开始看,我们在 kernel/proc.c 中可以找到 fork() 的实现:
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
int
fork(void)
{
int i, pid;
struct proc *np;
struct proc *p = myproc();
// Allocate process.
if((np = allocproc()) == 0){
return -1;
}
// Copy user memory from parent to child.
if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
//........................
return pid;
}
我们看 uvmcopy() 这部分,可以发现,这个函数就是做复制页表与物理内存的函数,我们在 kernel/vm.c 中可以找到。
我们知道,在这里我们并不需要新建物理内存然后映射页表,我们只需要把新页表映射到父进程的物理地址上就行,也就是说子进程的页表是父进程页表的一个 copy 。
随后,我们需要取消掉父子进程页表中的 PTE_W 位(将其变为不可写)。
最后的最后,我们在前面知道,一个 PTE 里面好心的开发商留了3位给程序员用来自定义状态,于是,我们在 kernel/riscv.h 中添加:
#define PTE_COW (1L << 8) // 1 -> for cow
这一个 PTE 位,用于标识哪些进程是 COW 的,哪些是真的被设置了只读的(这个很重要,因为如果不是COW但是被设置成了只读的你是不能更改的)
最后,uvmcopy 的代码如下:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz) {
pte_t* pte;
uint64 pa, i;
uint flags;
for (i = 0; i < sz; i += PGSIZE) {
if ((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if ((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
*pte = (*pte & (~PTE_W)) | PTE_COW;
flags = (flags & (~PTE_W)) | PTE_COW;
if (mappages(new, i, PGSIZE, (uint64)pa, flags) != 0) {
goto err;
}
}
return 0;
从书上我们知道,如果子进程想写了,但是会发现自己的页表被设置为只读,这个时候就会触发page fault 进入内核做进一步处理。
所以我们下一个需要修改的函数应该是 kernel/trap.c 中的 usertrap(),但像这种 page fault 它的 scause 应该是多少呢?
查文档或者直接运行
cowtest看看bug里面的scause等于多少就知道了注意,这个
pid的次序,shell是fork一个子进程来执行命令/函数的,所以中间有一个是shell的子进程
不管用什么方法,我们最终知道了这种情况的 scause 应该是 0xf,所以我们在 usertrap() 中特判这种情况并进行处理:
if (r_scause() == 8) {
// system call
if (p->killed)
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sstatus &c registers,
// so don't enable until done with those registers.
intr_on();
syscall();
}
// add here
else if (r_scause() == 0xf) {
uint64 va = r_stval();
if (cowfault(p->pagetable, va) < 0) {
p->killed = 1;
}
}
这里需要这个
va来知道出问题的到底是哪一页
然后,我们在 cowfault 这个函数中做进一步处理:
int
cowfault(pagetable_t pagetable, uint64 va) {
if (va >= MAXVA)
return -1;
pte_t* pte = walk(pagetable, va, 0);
if (pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0 || (*pte & PTE_COW) == 0)
return -1;
uint64 pa1 = PTE2PA(*pte);
uint64 pa2 = (uint64)kalloc();
if (pa2 == 0) {
printf("kalloc failed\n");
return -1;
}
memmove((void*)pa2, (void*)pa1, PGSIZE);
*pte = PA2PTE(pa2) | PTE_R | PTE_V | PTE_U | PTE_COW | PTE_X | PTE_W;
kfree((void*)pa1);
return 0;
}
注意,这里我们用了
kernel/vm.c walk()函数,我们需要在kernel/defs.h中对这个函数进行注册(不然没法用)
在这里,我们首先需要对 va 进行特判,防止系统进入 panic(因为如果大于 MAXVA 的话就说明应该是进程出问题了,这个时候你直接结束进程就行,不需要做任何处理)。
随后,我们需要对 PTE 进行判断,具体而言我们需要判断 PTE_V, PTE_U 和 PTE_COW 这三位,前两位是常规判断,必须要满足的,第三位是用来分辨的(上面已经解释过了)。
如果这个 PTE 满足所有条件的话,说明这个时候我们需要为子进程分配物理地址了,并且新分配的物理地址里面的值和父进程一致,我们需要进行一个复制(使用 memmove)。然后我们对子进程的 PTE 进行设定(可读可写可执行可访问……),最后我们需要释放原来的物理地址。
看到这里,我们知道一定存在一个问题:如果我们释放了原来的物理地址,不就相当于释放了父进程的物理地址吗?那父进程怎么办(直接变成无根之水)。因此我们可以运行一次测试来看看会发生什么。
这里我不放演示的过程了(因为实验都做完了懒得重新弄一遍了),但是你一定会看见一个
bug的,而且应该是父进程报的错(看pid可以看出来)
这个时候我们就需要去 kernel/kalloc.c 中修改 kfree() 了。
我们知道,现在的问题就是,如何分辨子进程和父进程,到底应该怎么释放物理页面?(因为一个父进程可以拥有很多个子进程)
我们提出了一个想法,我们新建立一个数组 refcount 来表示物理页面被引用的数量,如果被引用数为 $0$,就表示说这个物理页面是没人用的,否则是有进程正在使用这个物理页面。
于是,我们就可以在分配页面的时候对某个物理页面的 refcount 加 $1$ ,释放的时候减 $1$ ,直到 refcount 值为 $0$ 的时候才真的释放了页面。
这样,我们需要修改的函数就有 kfree() , kalloc():
int refcount[PHYSTOP / PGSIZE];
// Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit above.)
void
kfree(void* pa) {
struct run* r;
if (((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
//add here
acquire(&kmem.lock);
int pn = (uint64)pa / PGSIZE;
if (refcount[pn] < 1)
panic("kfree ref");
refcount[pn] -= 1;
int tmp = refcount[pn];
release(&kmem.lock);
if (tmp > 0)return;
// ....................
}
// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void*
kalloc(void) {
struct run* r;
acquire(&kmem.lock);
r = kmem.freelist;
// add here
if (r) {
kmem.freelist = r->next;
int pn = (uint64)r / PGSIZE;
if (refcount[pn])
panic("kalloc ref");
refcount[pn] = 1;
}
release(&kmem.lock);
// ..................
}
这里我们需要用锁来保证同一时间只有一个进程对 refcount 也就是临界区进行操作(如果清楚进程的同步异步应该会对这个问题很清楚)
我们注意到,在 kalloc() 中,我们只是将 refcount 变为 $1$ 了而已,并没有做任何加的操作,那我们应该在哪里对引用数增加呢?
显然应该是在 uvmcopy() 里面,于是,我们在 kernel/kalloc.c 中添加一个函数:
void
incref(uint64 pa) {
int pn = pa / PGSIZE;
acquire(&kmem.lock);
if (pa >= PHYSTOP || refcount[pn] < 1)
panic("incref");
refcount[pn] += 1;
release(&kmem.lock);
}
然后将其注册在 kernel/defs.h 中,并在 uvmcopy()的最后添加:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz) {
pte_t* pte;
uint64 pa, i;
uint flags;
for (i = 0; i < sz; i += PGSIZE) {
if ((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if ((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
*pte = (*pte & (~PTE_W)) | PTE_COW;
flags = (flags & (~PTE_W)) | PTE_COW;
if (mappages(new, i, PGSIZE, (uint64)pa, flags) != 0) {
goto err;
}
//add here
incref(pa);
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
这样就大功告成了
于是我们进行测试,发现,我们没法过掉最后一个测试,他直接乱序了……
我们查看 user/cowtest 中的测试,发现问题应该是出在了 write 这个函数上,其实简单的猜猜也能发现问题,但是我觉得可以看看视频的思路,一步一步来排除问题。
我们知道问题肯定是出在了 copyout() 对 COW 的处理上,因为我们压根没处理进行了 COW 的进程,所以在这里,我们修改为:
int
copyout(pagetable_t pagetable, uint64 dstva, char* src, uint64 len) {
uint64 n, va0, pa0;
while (len > 0) {
va0 = PGROUNDDOWN(dstva);
if (va0 >= MAXVA)
return -1;
pte_t* pte = walk(pagetable, va0, 0);
if (pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0)
return -1;
// add
if ((*pte & PTE_COW) != 0) {
if (cowfault(pagetable, va0) < 0)
return -1;
}
// ..................
}
return 0;
}
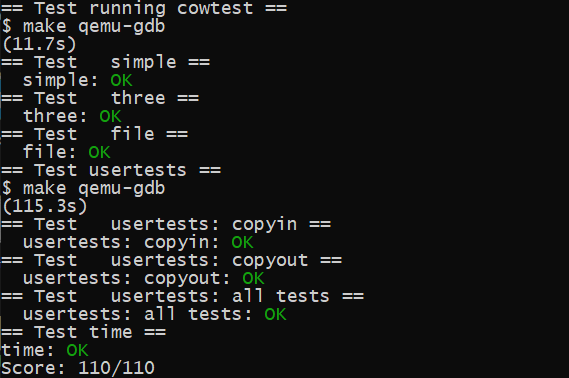
这样,我们就能通过所有测试了。
# 实验结果